python正则匹配常用到的函数主要主要有:
- fullmatch/match,返回re.Match对象,Match对象调用group(0)返回整个匹配,调用group(1)或者group(2)等依次返回括号内的匹配
- search,返回re.Match对象
- findall,返回列表包含括号内的匹配
- finditer,返回re.Match迭代器
示例代码如下:
1 | import re |
返回结果如下:
1 | None |
python正则匹配常用到的函数主要主要有:
示例代码如下:
1 | import re |
返回结果如下:
1 | None |
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
ELMo(Embeddings from Language Models)是发表在NAACL2018的论文Deep contextualized word representations提出来的模型,属于feature-based预训练语言模型,其后的ULM-fit与其模型基本一致,但在训练和迁移阶段使用了更多的分层适用的概念,属于fine-tuning预训练语言模型。
ELMo模型的简略模型结构图如下
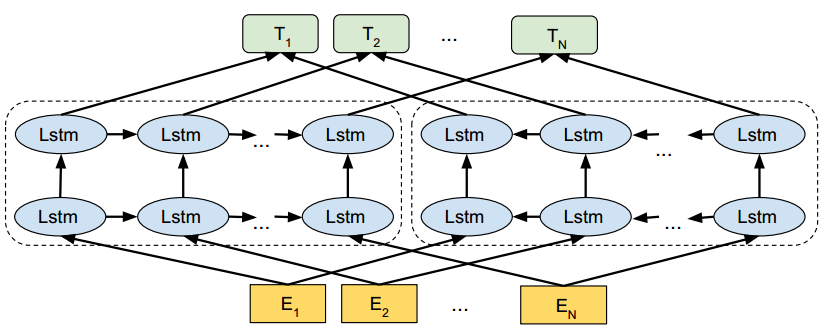
主要分为两大模块:
下面分别给出这两个模块的一些细节
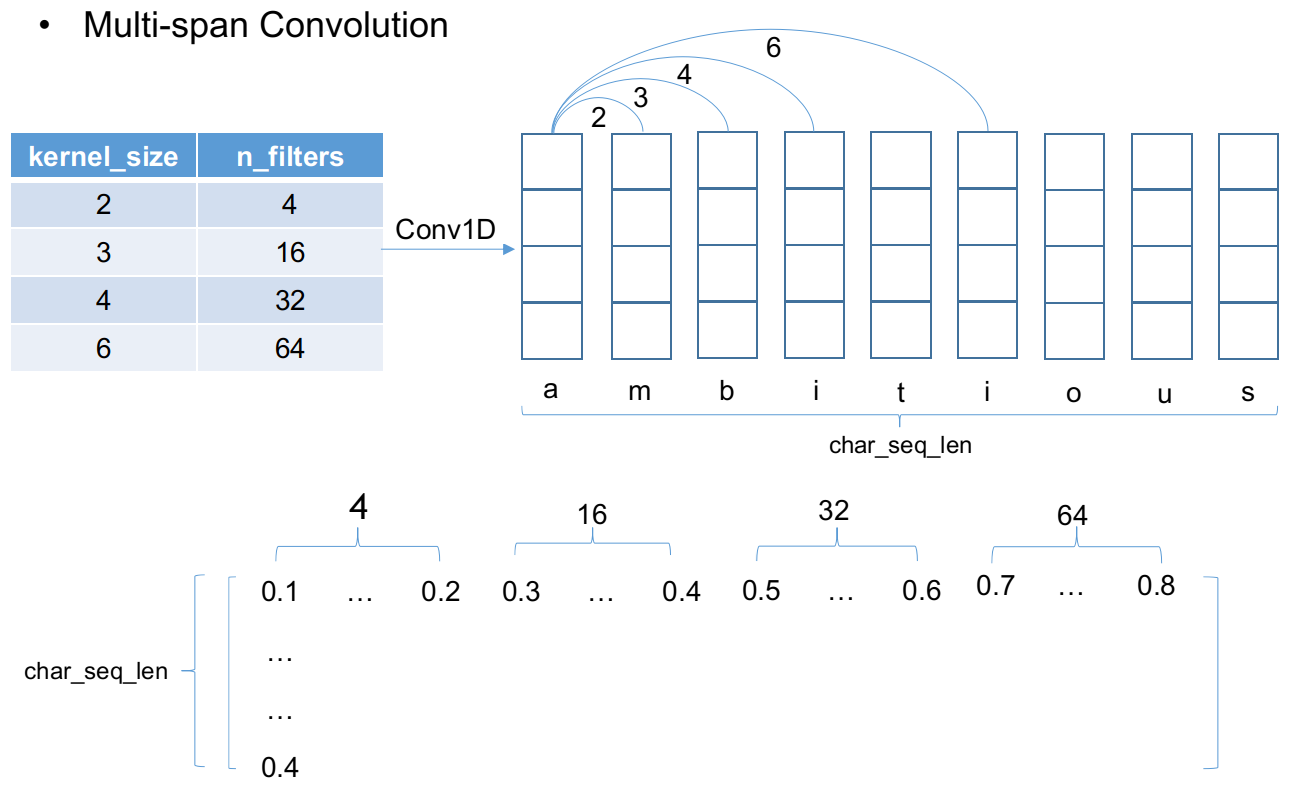
ELMo模型的token representation采用了character embedding,拥有更强大的表示能力,并且使用多个不同跨度的卷积核进行一维卷积,不同kernel卷积得到的不同表示拼接在一起,然后经过两层highway network得到最终的预处理编码表示。下图是一维卷积获取character embedding的具体操作示意图
多跨度多kernel的卷积拼接获取character embedding的具体操作示意图如下
将拼接得到的character embedding输入到两层highway network进行处理,highway network其实就是CV领域著名的ResNet中使用的残差单元的原型,highway network模型结构图如下
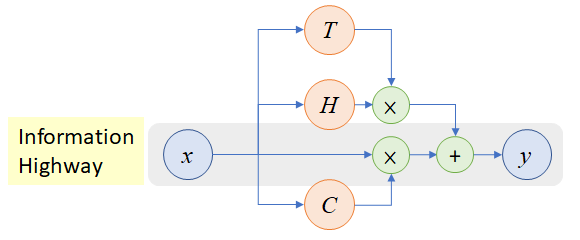
highway network的表达式描述为
特别地,当$C=1-T$
其中$H,T,C$都是非线性转换,$W_H,W_T,W_C$分别为它们对应的参数。
下图是LSTM的模型结构试图以及每个control gate的计算式
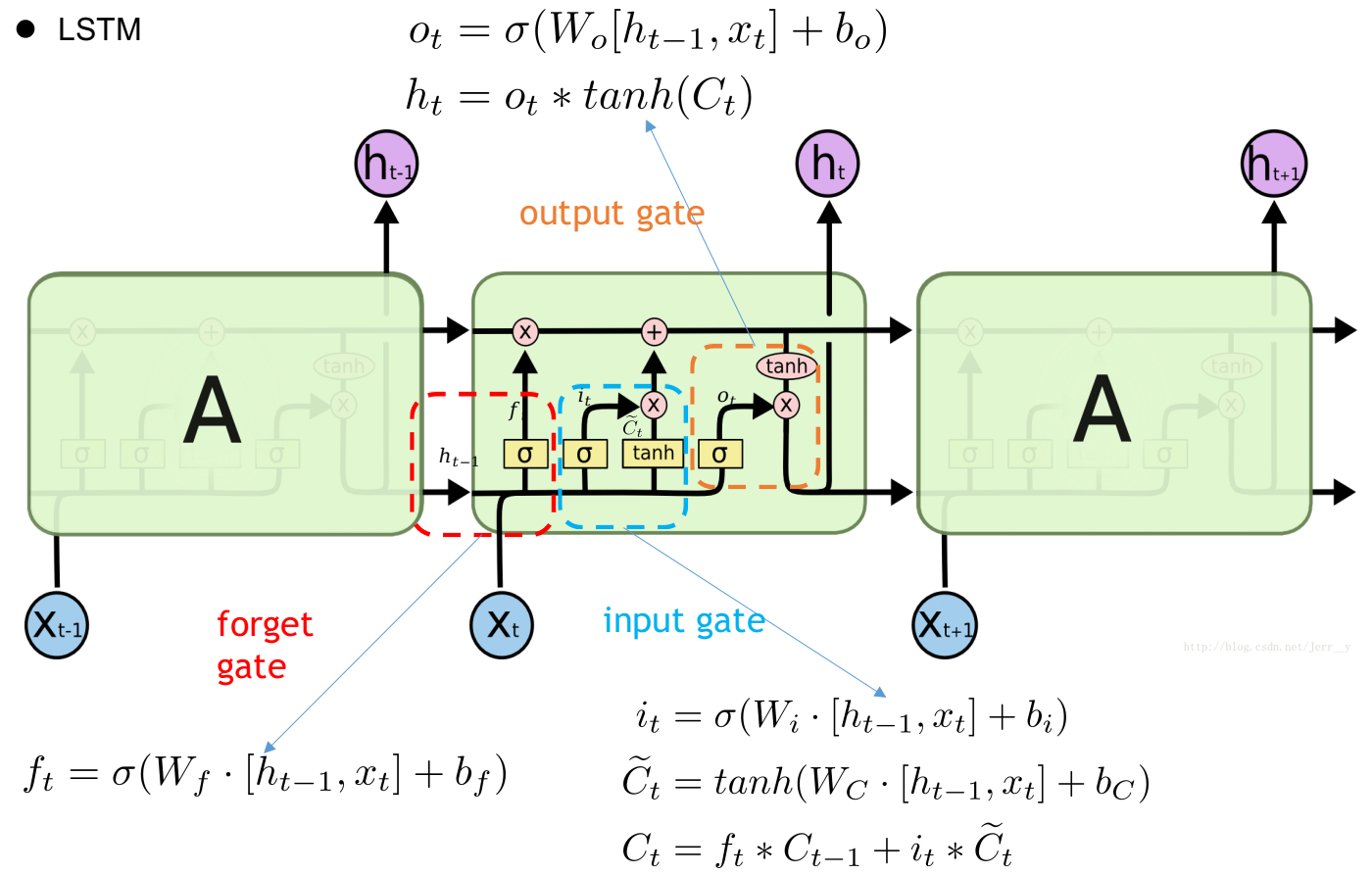
BiLSTM则是使用一个正向一个逆向的LSTM处理sequence得到每个token的hidden state进行拼接作为这个token最终的输出。而Multi-BiLSTM顾名思义就是多层的双向LSTM,将当前这一层BiLSTM的正反向hidden state拼接输出作为紧邻的上一层的输入,最后一层的输出才是token最终的输出。
ELMo使用feature-based的方式应用到下游任务,就是将模型输出表示加入(一般是拼接)到任务模型中的某一层中或多层中以增强任务模型对文本的表示能力。具体方式在这里我直接引用原文更好理解:
a L-layer biLM computes a set of 2L + 1 representations
$h{k,0}^{LM}=[x{k}^{LM},x_{k}^{LM}]$ for token representation
$h{k,j}^{LM}=[\overrightarrow{\mathbf{h}}{k, j}^{L M}, \overleftarrow{\mathbf{h}}_{k, j}^{L M}],j \gt 1$ for each biLSTM layer, compute a task specific weighting of all LM layers
$s_{j}^{\text {task}}$are softmax-normalized weights and the scalar parameter $\gamma^{\text {task }}$allows the task model to scale the entire ELMo vector.
下游任务可以根据优化的目标函数对ELMo表示的权重$s_{j}^{\text {task}},\gamma^{\text {task }}$进行学习得到合适的权重。
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
在transformer model出现之前,主流的sequence transduction model是基于循环或者卷积神经网络,表现最好的模型也是用attention mechanism连接基于循环神经网络的encoder和decoder.
Transformer model是一种摒弃了循环及卷积结构,仅仅依赖于注意力机制的简洁的神经网络模型。我们知道recurrent network是一种sequential model,不能很好地解决长距离依赖的问题(序列过长时,信息在序列模型中传递时容易一点点丢失),并且阻碍了parallelism within train example.而transform最引人瞩目的一点正是很好地解决了长距离依赖的问题,通过引入自注意力机制(self-attention)使得对依赖的建模与输入输出序列的距离无关,并且支持train exmaple内部的并行化。注意力机制可以参考之前写的notes of cs224n lecture8.
下图1是transformer的模型架构图
![]()
左边是encoder,右边是decoder,各有6层,下面我将讲解个人觉得比较重要的几个点。
![]()
如上图2左边所示即为dot-producted attention的一般形式,在transformer中,初始Q, K, V即为一个句子所有的subword编码构成的矩阵(seq_len, d_model),其中d_model是subword的编码长度。Deocder的第二个Multi-Head Attention中的Q, K, V会有所不同,在讲解Multi-Head Attention是提到。下面是dot-producted attention的数学表达形式
这里除以是因为在与additive attention(之前写的文章有提到)对比时发现较小时,这两种注意力机制表现相似,但是当较大时dot-producted attention不如additive attention。最后分析原因发现较大时点乘结果矩阵元素在数量级很大,使得softmax函数求导的梯度非常小。下面是原论文的一个解释
To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product, , has mean 0 and variance dk.
如上图2右边所示即为Multi-Head Attention的结构图。它的中心思想就是将原来的转换成num_heads个shape为(seq_len, d_model/num_heads)的,然后再为每个head执行dot-producted attention的操作,最后再将所有head的输出在最后一个维度上进行拼接得到与对原始输入执行单个dot-producted attention操作后shape一致的结果。下面是Multi-Attention的数学表达形式
其中,,而
在transformer中使用h=8个parallel attention heads.对于每个head使用. 我看tf official tutorial of transformer实现中并没有为学习转换矩阵,而是先对作一个线性转换到的编码,然后将的编码表示划分成h份,然后输入到各自的head中进行处理。Multi-Head Attention机制允许模型在不同位置共同关注来自不同表示子空间的信息。
Decoder中包含两层的Multi-Head Attention(MHA),第二层的MHA不再使用初始的作为输入,而是使用上一层MHA的输出作为,Encoder最后一层(第6层)的输出作为.
无论encoder还是decoder都需要使用mask屏蔽掉不必要的信息干扰。
对于encoder,由于我们传入的数据是padded batch,因此需要对padded的信息进行mask,具体mask的位置放置在dot-producted attention的scale即之后softmax之前,对需要mask的位置赋值为-1e9,这样在softmax之后需要mask的位置就变成了0,就像是指定mask的位置进行dropout.
对于decoder,每一层包含两个Multi-Head Attention(MHA),第一个MHA同样需要对padded信息进行mask,除此之外还要对output中还未出现的词进行mask,保证只能根据前面出现的词信息来预测后面还未出现的词。将两个mask矩阵叠加之后输入到dot-producted attention单元中的scale之后用于屏蔽非必要信息。第二个MHA由于使用Encoder最后一层的输出作为,所以需要对Encoder初始输入的padded信息进行mask,同样是在dot-producted attention单元中的scale之后操作。
encoder和decoder的输入是两套独立的embedding(例如translation task,分别是原语和目标语subword的Embeddings),embedding的维度为,论文中的base model设为512,big model设为1024.在embedding输入模型前逐元素乘以,因为在dot-producted attention中 .
由于transform model不包含循环和卷积网络,为了使模型能利用sequence的顺序信息,必须加入序列中每个subword的相对或者绝对位置信息。因此引入了Positional Encoding,它保持和embedding一样维度,具体encoding的方式有很多种,主要分为学习的和固定的(learned and fixed)。在论文中使用了固定的无须学习的positional embedding,使用不同频率的cos和sin函数如下
其中,pos是token position in sequence,i是dimension position.之所以选择cos和sin函数是因为对于固定的偏置量能够表示为的线性函数,假设它可以很容易学习到相对位置引入的信息。使用cos和sin的另一个原因是它允许模型推断比训练过程中遇到的更长的序列。论文中作者表示也使用了learned positional embeddings,但是与上述的fixed positional embeddings结果基本一致,所以最终采用了fixed positional embedings,这种方式更高效,减少训练开销。
最终作为模型输入的是token embeddings + positional embeddings,然后套一层dropout.
如上图所示,使用self-attention机制主要有三点原因
由于self-attention的complexity per layer为,考虑非常长序列的极限情况,可以限制self-attention在计算时只考虑输入序列K,V中的r个邻居即可将complexity per layer限制在,这就是上图2中的Self-Attention(restricted).
WMT 2014 English-German datasset和WMT 2014 English-French dataset,数据集官网download,论文使用其中的newstest2013作为验证集(development dataset),newstest2014作为测试集(test dataset)。base model平均最后5个checkpoint的结果,big model平均最后20个checkpoint的结果。由于数据集太过庞大,训练代价很大。论文中使用8 NVIDIA P100 GPUs,base model训练100000 steps耗时12h,big model训练300000 steps耗时3.5 days.
论文中主要使用了两种正则化手段来避免过拟合并加速训练过程。
在每一residual Multi-Head Attention之后,Add&Norm之前进行dropout,以及add(token embedding,positional encoding)之后进行dropout,FFN中没有dropout,base model的dropout rate统一设置为0.1,big model在wmt14 en-fr数据集上设置为0.1,在en-de数据集上设置为0.3
Label Smothing Regularization(LSR)是2015年发表在CoRR的paper:Rethinking the inception architecture for computer vision中的一个idea,这个idea简单又实用。假设数据样本x的针对label条件概率的真实分布为
这使得模型对自己给出的预测太过自信,容易导致过拟合并且自适应能力差(easy cause overfit and hard to adapt)。解决方案:给label分布加入平滑分布,一般取均匀分布就好,于是得到
映射到损失函数cross entropy有
由上式可知,LSR使得不仅要最小化原来的交叉熵H(q,p),还要考虑预测分布与之间差异最小化,使得模型预测泛化能力更好。transformer的论文中指定。下表是使用LSR和未使用LSR在tensorflow datasets的ted_hrlr_translate/pt_to_en dataset上bleu score对比
| bleu on validation dataset | bleu on test dataset | |
|---|---|---|
| beam_search | 0.415/41.5 | 0.420/42.0 |
| beam_search + label_smooth_regualrization | 0.473/47.3 | 0.468/46.8 |
可以看到使用了LSR在验证集和测试集上都取得了比更好的bleu score.但是LSR对perplexity不利,因为模型的学习目标变得更不确切了。
在multi-head attention之后使用layer normlization可以加速参数训练使得模型收敛,并且可以避免梯度消失和梯度爆炸。相比BatchNormalization,LayerNormalization更适用于序列化模型比如RNN等,而BatchNormalization则适用于CNN处理图像。
Transformer使用Adam optimizer with .学习率在训练过程中会变动,先有一个预热,学习率呈线性增长,然后呈幂函数递减如上图所示,下面是学习率的计算公式
论文中设置warmup_steps=4000.也就是说训练的前4000步线性增长,4000步后面呈幂函数递减。这么做可以加速模型训练收敛,先以上升的较大的学习率让模型快速落入一个局部收敛较优的状态,然后以较小的学习率微调参数慢慢逼近更优的状态以避免震荡。
Transformer是NLP在深度学习发展历程上的一座里程碑,目前主流的预训练语言模型都是基于transformer的,逐渐取代了LSTM的位置,深入理解transformer的细节对后续NLP的学习非常重要。
Transformer最大的亮点在于不依靠RNN和CNN,通过引入self-attention机制,很好地解决了让人头疼的长距离依赖问题,使得输入和输出直接关联,没有了RNN那样的序列传递信息损失,输入输出之间经过的的路径长为常数级,与输入序列长度无关,上下文信息保留更完整。因此tranformer是非常强大的文本生成模型,应用于MT, 成分句法分析(constituency parsing)等效果非常好。
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
统计机器翻译(Statistical Machine Translation,SMT)出现并流行于1990s~2010s,1990s以前的MT工作大部分都是基于规则的(rule-based),使用双语词典作为映射,最早可以追溯到1950s。SMT的main idea如下图所示
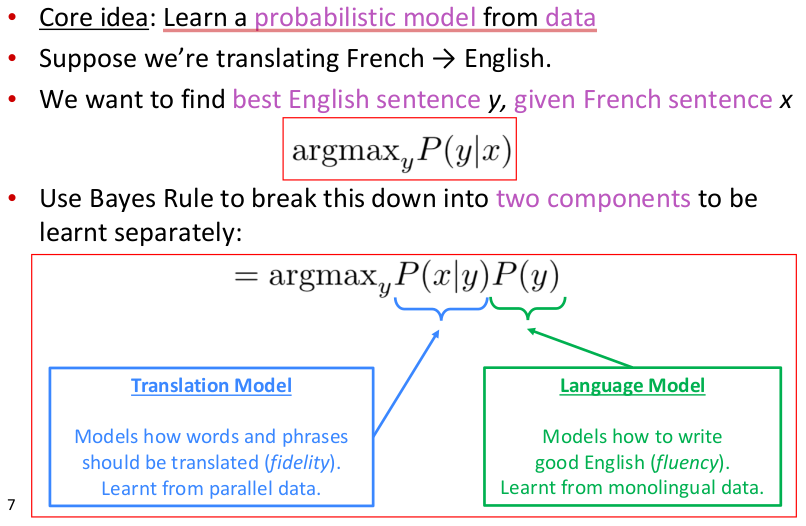
SMT将模型划分为2部分进行学习,左部主要用于确保翻译后的句义保真度,尽可能学习到原句的真实含义。而右部主要用于确保翻译后句子的流畅度。机器翻译还有一个难题就是对齐(alignment),原句和目标语句之间的语法可能差异很大,使得词序排列分布差异很大,要学习原句词与目标句词之间的对齐方式是一件非常棘手的事。定位alignment关系非常复杂,因为alignment有一对多、多对一以及多对多的关系,SMT通过加入一隐变量a用于专门学习alignment,即将$P(x|y)$进一步划分为$P(x,a|y)$,其中a物理含义是原句与目标句之间word-level correspodence.
seq2seq model的结构如下图所示
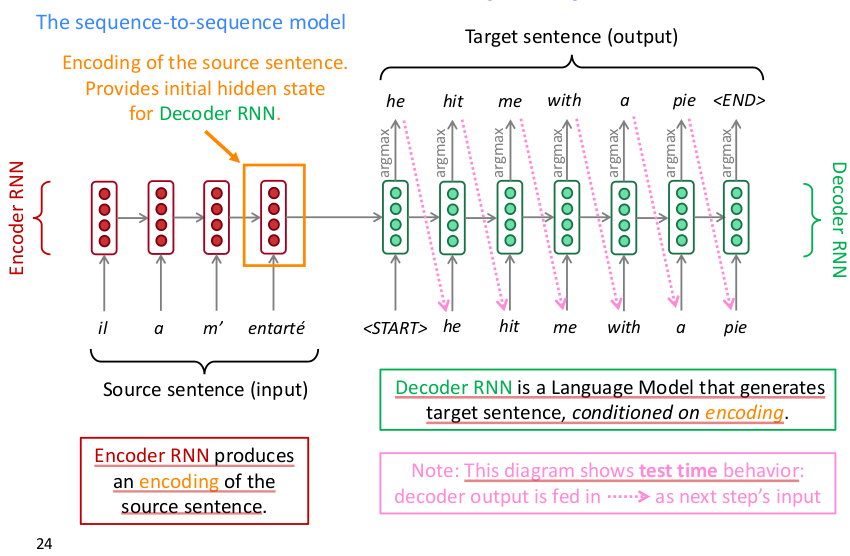
从上图看seq2seq应用于NMT的方式一目了然,这是一个auto-regressive model,通过历史序列信息学习预测当前词,loss为交叉熵。seq2seq无须对输入数据进行预特征提取,直接将原始序列输入即可得到目标序列输出,一个典型的端到端黑箱模型。正由于其简便易用,得到了很多应用,seq2seq model还能应用于

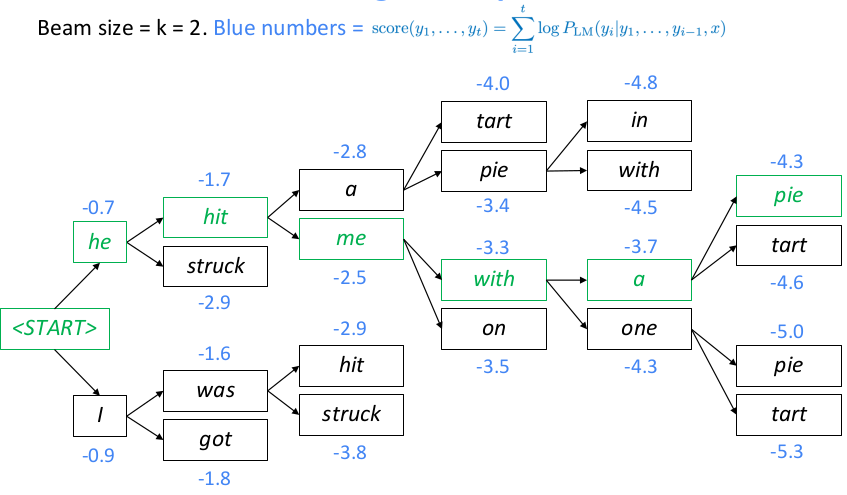
一般beam size设置越大,寻找到的结果更优,但不一定是最优,只有搜索所有路径才可以得到最优解,一直搜索直到预测到结束标记,概率值为language model的log probability的前缀和,因此序列越长log probability的和可能越小,结果要除以对应序列长度来比较候选序列。通常可以设置概率阈值、候选序列个数、预测序列长度限制来作为搜索的终止条件。由于beam search容易使用来自训练集中的常见短语和重复文本,因此Hierarchical Neural Story Generation这篇文章提出使用top-k random sample scheme的方法,简单概括就是先选出LM生成概率最高的k个词,然后从这top-k个词中随机采样一个词作为下一个序列生成词,重复上述步骤直到生成终止词。 MT task的评估一般采用BLEU,可以参考assignment4 handout或者paper bleu,NLTK提供了基于句子和语料库计算bleu score的API,注意计算整个corpus的bleu不是求corpus中每个句子bleu的均值,而是累加每个句子的ngrams统计信息到同一个分子分母中统一计算得来。bleu取值范围[0,1],但是论文中都习惯将bleu乘以100后保留一位小数来表示。
NMT相比SMT的优点如下

NMT缺点在于不可解释的黑箱,难以调试,有结果超乎预料的风险。
seq2seq model简便以用,但是瓶颈也很明显如下图所示
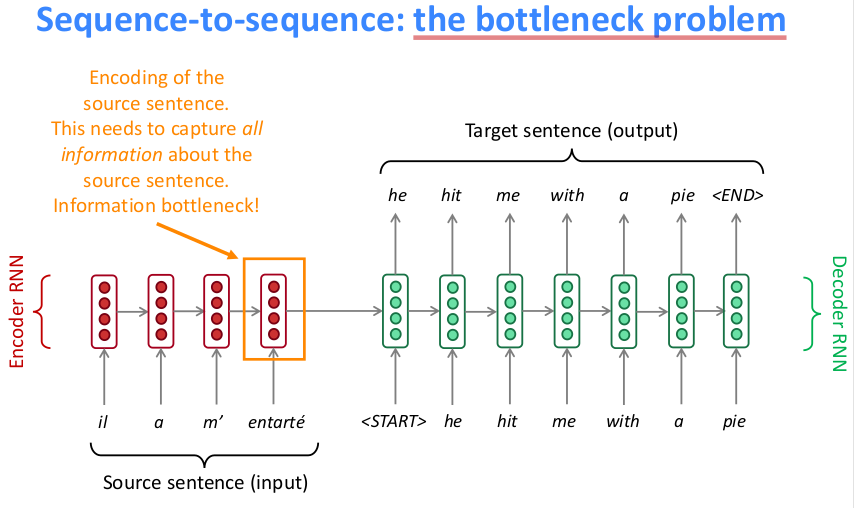
最后一个词输出的hidden state需要囊括句子的所有信息,而LSTM对于长距离问题又无法很好地解决,因此最终的hidden state肯定丢失了很多的信息。为了能很好的提取前面所有词的编码信息,需要引入注意力机制
core idea: on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence
seq2seq引入attention的具体方式如下所示
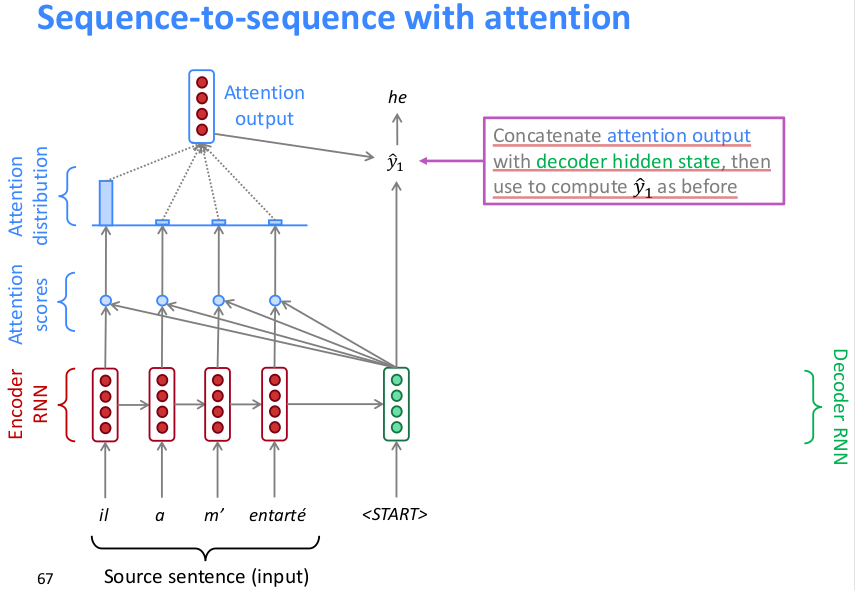
如上,将原句编码后的hidden state向量与原句中每个词的编码向量作点积运算得到每个词的attention score(scalar),然后softmax所有词的attention scores得到attention distribution(上图可以看到attention在下一相关词上分布最多),然后再用attention distribution对词编码向量作加权求和得到attention output,然后concat到decoder的hidden state预测下一个词。下图是下一层的执行方式
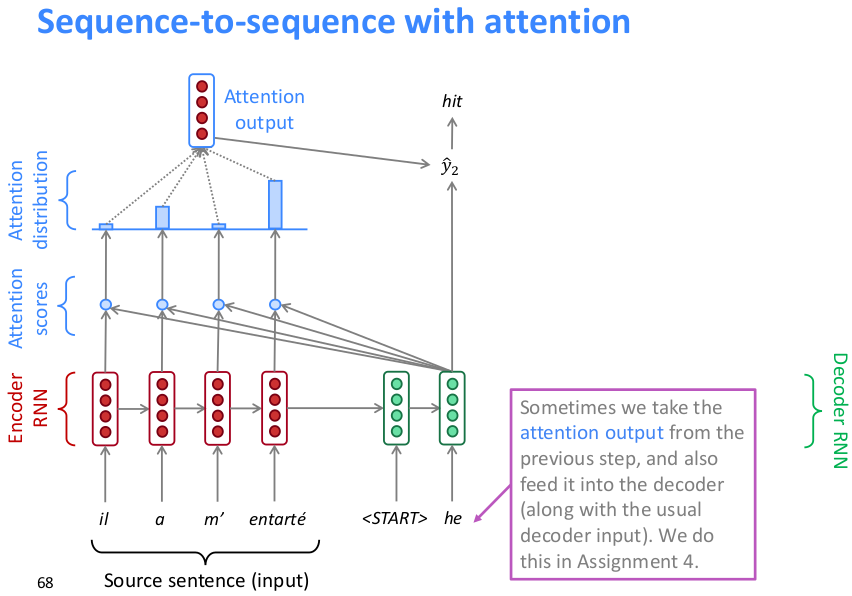
将前一层的attention output和前一层的预测输出词向量concat作为这一层的输入,由于此时hidden state是拼接的要取原句子编码向量那一段输入到attention机制中,得到的attention output同样concat到当前的句子编码中用于预测下一词。
attention正是通过直接与句子中所有word embedding进行点积(direct connection),并将attention distribution用于句子中所有词向量的加权求和从而解决了LSTM无法解决的长距离依赖问题,使得hidden state包含了句子更丰富的信息,从而能更好得预测下一个词。
attention不仅是用于seq2seq model,它有更general的用途如下

attention mechanism有三种常见变体形式如下


作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
随着深度神经网络的发展,深度学习在文本生成比如nueral machine translation(NMT)以及question answer(QA)等任务中突破了传统方法的瓶颈,在很多数据集上都取得了state-of-the-art(SOTA)的效果。
我们知道神经网络输入层必须接收数字形式的信息,所以必须将文本形式的词嵌入成向量。通常会设定一个词汇表大小,对于词汇表中所有词有对应的向量表示。而由于一种语言涵盖的词汇太多,以及处理的文本数据本身就不规范(比如web数据),从而无法覆盖所有的词汇,在对corpus中的词进行向量map时会出现out of vocabulary(OOV)的现象。以往的做法是设置一个特殊字段(比如UNK)来表示所有OOV的词汇,这种做法可谓相当粗糙,那有没有更细致微妙的处理方法呢?答案当然是有的,很多从事NLP研究的工作者在这个方面开展了不少的工作。一种方法是从word embedding扩展到character embedding,另外一种方法是将word拆分成有意义的更小的词素也就是wordpieces,两个word可能不相同,但是他们可能包含相同的wordpieces,这样对于OOV的word,找到其对应的wordpieces的向量added or averaged也可以蕴含该word的word sense。接下来分别介绍这两种方法。
在没出现character embedding之前可能会觉得仅用少量的字符向量就可以表示含有丰富含义的词向量会有点不可思议,但借助于神经网络对特征强大的组合能力,使得这一切成为了可能。目前对word中的characters进行组合的方式目前主要有convolutional network和LSTM network两种。下面分别介绍这两种方法以及混合使用word-character embedding的模型。
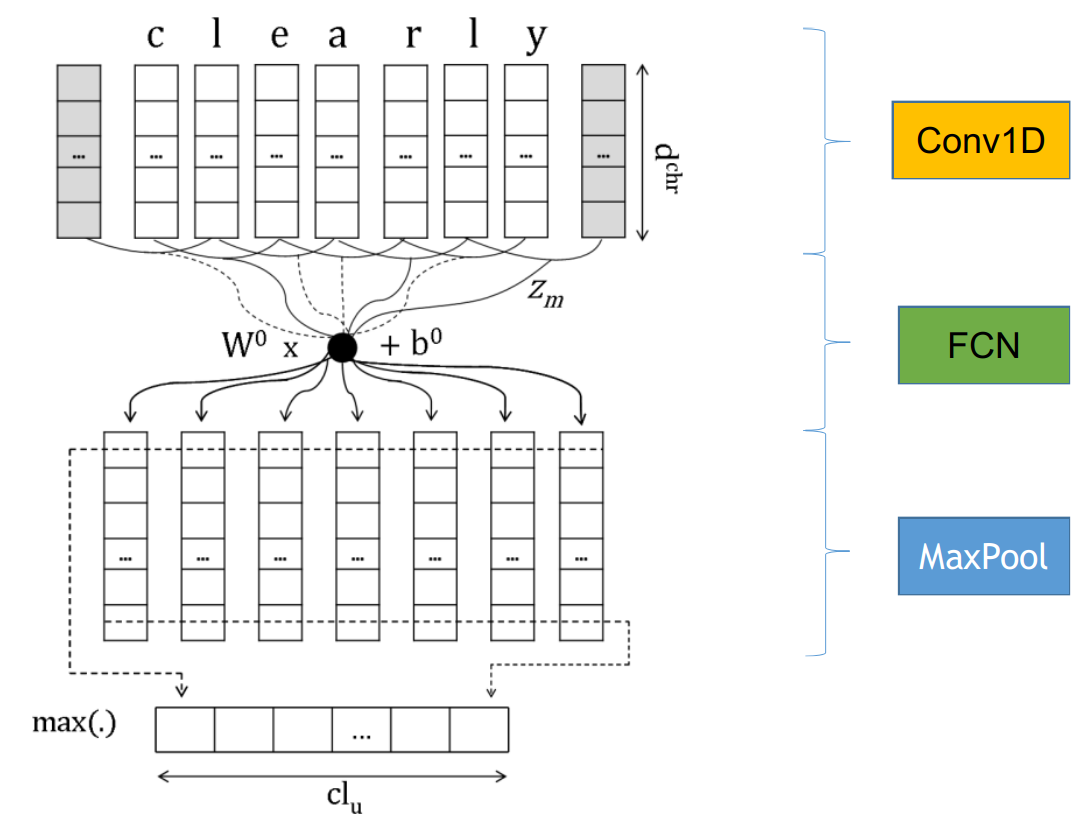
Learning Character-level Representations for Part-of-Speech Tagging C´ıcero,这篇文章发表于JMLR2014,应该是最早的使用卷积神经网络处理char embedding的,模型主要分三层conv+fcn+maxpool,具体的结构图如下
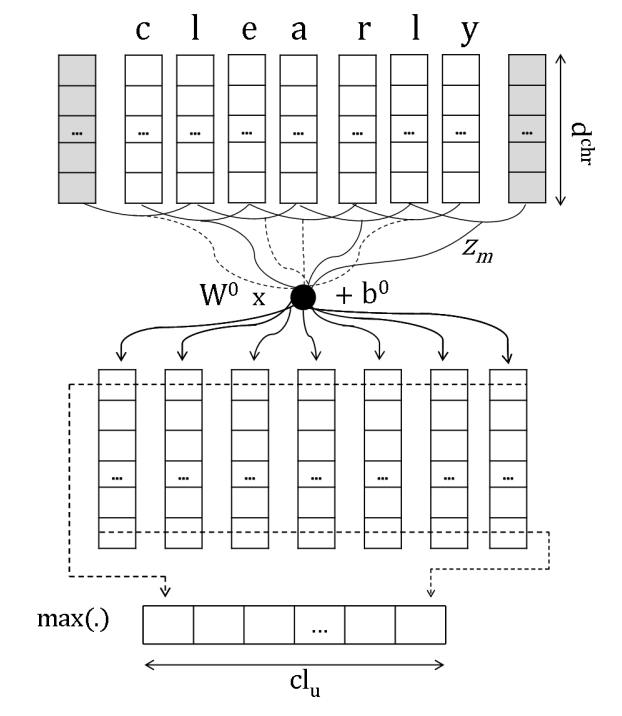
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation,这篇文章发表于EMNLP2015,使用LSTM网络处理char embedding,并将其很好得应用于language model和POS tagging,具体的模型结构如下
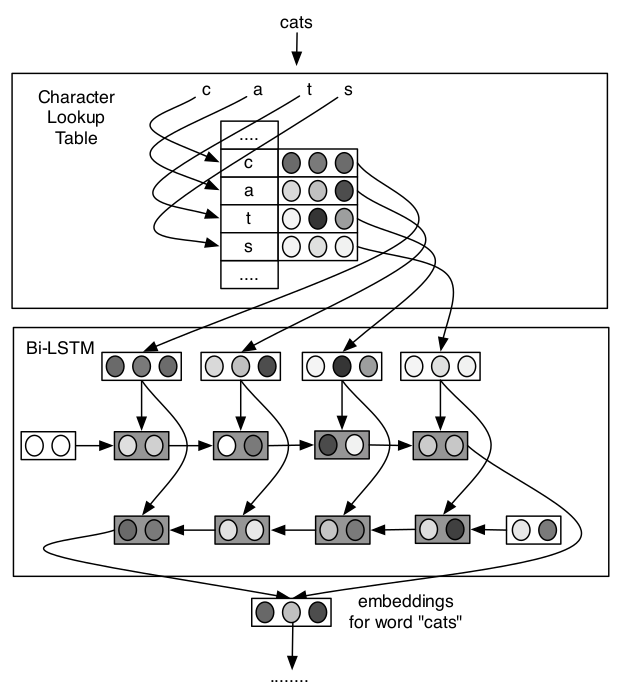
模型使用双向LSTM对character embedding进行处理并将两个方向最终的隐状态向量拼接作为word embedding输出。
character embedding与word embedding不同在于:word embedding是在巨大语料集上学习好的,然后再用于NLP的各种下游任务,而character embedding是随机初始化的,在学习下游任务目标的同时学习character embedding。考虑到word embedding和character embedding各自都包含了有用的信息,因此Christopher D. Manning等人提出了综合使用word embedding和character embedding的混合模型Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models,这篇文章发表于ACL2016,模型使用单向LSTM网络,具体结构如下
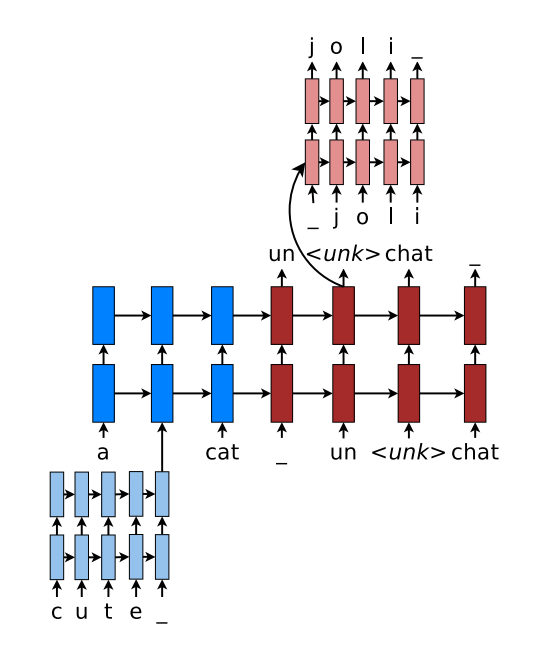
对于输入序列中的OOV word使用双层LSTM处理其对应的char embedding得到的输出作为word embedding,对于输出序列中的\
wordpieces这个名字取得很形象,说白了就是将词划分成片表示,但可不是随便划分。目前的划分方法主要有两种:
Neural Machine Translation of Rare Words with Subword Units,这篇文章发表于ACL2016。文章思路其实很简单,初始化所有的wordpieces为单个字符,就是统计相邻两个wordpieces在所有word中共现频率,然后合并出现频率最高的wordpieces,直到当前词汇表满足设定的大小。注意,合并起来的wordpieces的所有前缀都要包含进词汇表中。下面是BPE算法的python代码

代码一目了然,但正是这么简单的方法却在很多NLP下游任务上取得了很不错的效果,因而得到了广泛的应用,毕竟简单而又好用的谁不喜欢呢!!
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates,这篇文章发表于ACL2018。文章基于输入语料库建立unigram model,使用EM算法迭代,每次保留去除该词后使得语言模型的perpelxity损失最大的前80%的词,迭代计算直到当前词汇表满足设定的大小。
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing,这篇文章发表于EMNLP2018,在发表这篇文章之前,google也发表了一篇基于unigram language model的建立wordpieces词汇表的文章Japanese and Korean voice search,这篇文章发表于IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)2012。但SentencePiece这篇文章可谓集大成者,Google在这篇文章基础上开源了github: SentencePiece Package,它不仅包含常用的character和word embedding,并且实现了前述2种subword segmentation algorithms即BPE和unigram language model,Google真乃良心啊,这就为后面所有NLPer的工作提供了提供了一个统一的输入预处理工具。并且该工具还可以保存构建wordpieces的model,便于论文实验结果的再现(reproducibility,因为很多NLP模型对输入极其敏感,输入稍有偏差将导致结果迥然不同)。SentencePiece Package上手使用非常简单,下面给出代码:
1 | import sentencepiece as spm |
Train方法中的参数说明如下
--input: one-sentence-per-line raw corpus file. No need to run tokenizer, normalizer or preprocessor. By default, SentencePiece normalizes the input with Unicode NFKC, . You can pass a comma-separated list of files.--model_prefix: output model name prefix. .model and .vocab are generated.--vocab_size: vocabulary size, e.g., 8000, 16000, or 32000--character_coverage: amount of characters covered by the model, good defaults are: 0.9995 for languages with rich character set like Japanse or Chinese and 1.0 for other languages with small character set.--model_type: model type. Choose from unigram (default), bpe, char, or word. The input sentence must be pretokenized when using word type.执行上面代码后会在当前目录下生成subword.vocab和subword.model两个文件,下面给出加载模型进行编码解码的代码示例
1 | import sentencepiece as spm |
wordpieces以很巧妙的思想解决了OOV的问题,后面出现了大量的使用wordpieces作为embedding的工作。这里不得不提一下fastText: Enriching Word Vectors with Subword Information,这篇文章是facebook ai团队发表于TACL2017,这篇文章使用和word2vector一样的学习embedding的方法skip-gram,但是它是学习word的subword n-grams(文章中n设为3~6,就是word的所有连续的3~6grams) embedding,这样其它任务使用词向量出现OOV现象即可使用该词n-grams的subword embeddig累加来合成。那么如何训练subword n-grams 的embedding呢?就skip-gram进行讨论,假设center word为$w_t$,window word为$w_c$,则围绕$w_t$的loss为
其中,$\mathcal{N}{t,c}$ is a set of negative examples sampled from the vocabulary. 我们用$\mathcal{G}w \subset {1,…,G}$ 表示出现在w中的n-grams集合(3~6 grams in paper),$z{g}$表示$w$每个n-gram的embedding,$w$的向量表示为$z_g$的和,因此可得$s(w,c)$
该方法异常高效,train cost非常低,不同以往的word embedding学习需要海量的文本数据进行学习,fastText只需要word2vec方法的5%甚至1%的数据即可在许多任务上达到一致的效果。下图是word2vec的cbow方法以及fastText的skip-gram方法使用不同大小数据集训练后在word similarity任务上spearman rank表现对比
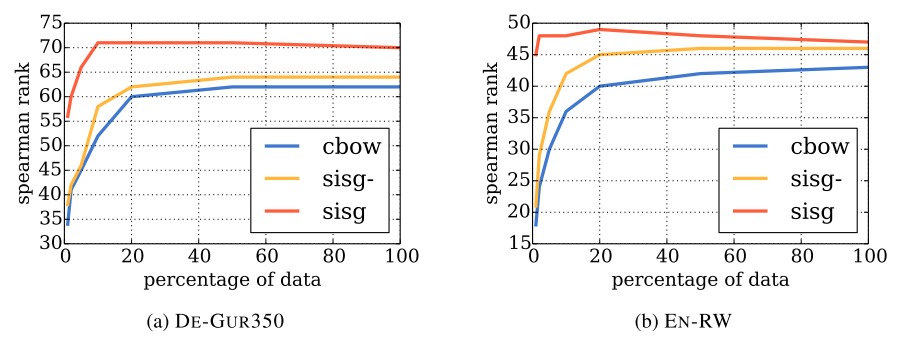
其中,sisg-是fastText使用null vector表示OOV word,而sisg是fastText使用summing subword n-grams表示OOV word,可以看到sisg使用少量数据之后即可效果基本就饱和了。fastText对于复合词多、词尾变化丰富、多形态词的语言,以及包含大量生僻词的语料库效果更为明显,因为这些很难直接用word embedding直接覆盖,非常适合使用subword n-grams来拼接表示。但是对于常见词使用直接word embedding效果会比subword n-grams embedding效果更好,如下图所示,可以看到在word similarity任务上,fastText在WS353 dataset上表现不如word2vec的cbow,because words in the English WS353 dataset are common words for which good vectors can be obtained without exploiting subword information.
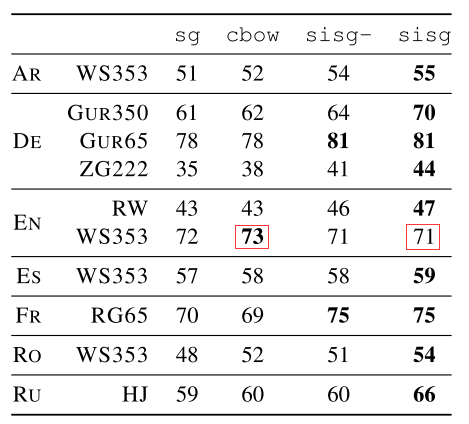
所以前面提到的Hybrid Word-Character Model也正是发现此问题后的进一步优化,能优先使用word embedding的就是用word embedding,否则使用character embedding或者wordpieces embedding。
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
后向传播(backpropagation)算法在深度学习中扮演了非常重要的角色,它能够从损失函数开始链式地对网络层中的权重进行梯度计算与更新。可以先参考维基百科: Backpropagation,文章很好地还原了深度神经网络(DNN)每一层网络从后往前的链式梯度计算关系。然后再结合下面这几张图理解每一层网络中每个单元的梯度具体计算与推导过程,假设前向计算公式$wx + b$.






上图是一个两层的全连接神经网络,其中是输入,是输出,输出在softmax之后计算交叉熵损失。下面给出详细计算隐藏层对应的权重梯度的过程,其中是batch size,是真实标签,是softmax激活后的输出
又因为
所以
除此之外,还有一个问题,交叉熵损失函数计算值只与标签1对应的输出相关,那么标签0对应输出的相关权重就无需计算梯度并进行更新了么?跑了一下上图两层全连接神经网络的demo程序,发现无论输出对应标签是0还是1,其相关权重梯度都不为0。通过对权重梯度的核算发现,对于标签0对应输出,虽然在交叉熵损失函数计算结果中没有得到体现,但是在后向传播梯度计算过程中,会采用$-(1-y_0)\log{(1-O_0)}$作为0标签相关权重梯度计算的损失,这点类似于逻辑回归损失函数,其中$y_0$为0,$O_0$为对应softmax输出。demo程序如下
1 | import torch |
Tips:
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
pssh提供OpenSSH和相关工具的并行版本。包括pssh,pscp,prsync,pnuke和pslurp。该项目包括psshlib,可以在自定义应用程序中使用。pssh是python写的可以并发在多台机器上批量执行命令的工具,它的用法可以媲美ansible的一些简单用法,执行起来速度比ansible快它支持文件并行复制,远程命令执行,杀掉远程主机上的进程等等。杀手锏是文件并行复制,,当进行再远程主机批量上传下载的时候,最好使用它。pssh用于批量ssh操作大批量机器;pssh是一个可以在多台服务器上执行命令的工具,同时支持拷贝文件,是同类工具中很出色的;比起for循环的做法,更推荐使用pssh! (注意需要安装 python 2.4 或以上版本)
下面是直接从源码进行编译安装的步骤,安装过程很快
1 | wget https://pypi.python.org/packages/60/9a/8035af3a7d3d1617ae2c7c174efa4f154e5bf9c24b36b623413b38be8e4a/pssh-2.3.1.tar.gz |
pssh --help可以查看命令参数选项:
1 | -l 远程机器的用户名 |
pssh、pscp、prsync、pnuke和pslurp的具体使用:
1 | 注:在使用工具前,确保主机间做了密钥认证,否则无法实现自动化,当然我们可以使用sshpass(yum install sshpass)配合pssh -A参数实现自动输入密码,但这要保证多台主机的密码相同,同时还要注意如果known_hosts没有信任远程主机,那么命令执行会失败,可以加上-O StrictHostKeyChecking=no参数解决,ssh能用的选项pssh也能用 |
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
卡特兰数又称卡塔兰数,英文名Catalan number,是组合数学中一个常出现在各种计数问题中的数列。该数在计算机专业中比较重要,有一些具体的应用实例。这篇文章主要分三部分:
假设h(0)=1,h(1)=1,catalan数满足递推式:
递归式背后有什么物理含义呢,这里以出栈序列问题进行说明:
问题描述:一个栈(无穷大)的进栈序列为1,2,3,…,n,有多少个不同的出栈序列?


作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
查看本机显卡
1 | lspci | grep -i VGA |
终端输出显卡名称,现在电脑一般都有集显+独显2块显卡,若都是nvidia公司的,后续如果安装openGL就不会冲突,因为openGL只支持nvidia的显卡,其他公司的会被openGL安装覆盖。我这里是intel集显,所以安装cuda的时候就不能安装openGL.
查看本机nvidia GPU型号
1 | lspci | grep -i nvidia |
到官网official nvidia driver下载对应自己系统版本和GPU型号的driver,cuda和nvidia driver的对应关系可以参考cuda vs nvidia-driver。我这里下载的GeForce GTX 1060,linux 64bit,game ready版本的driver。在真实安装之前还需要禁用系统现有的driver。
禁用nouveau driver
nouveau是ubuntu16.04默认安装的第三方开源驱动,安装cuda会跟nouveau冲突,需要事先禁掉,运行命令lsmod | grep nouveau后需要没有任何输出就代表禁掉了。具体禁用方法如下:
在/etc/modprobe.d中创建文件blacklist-nouveau.conf,在文件中添加以下内容
1 | blacklist nouveau |
命令行下执行sudo update-initramfs –u,然后在执行lsmod | grep nouveau,若无内容输出,则禁用成功,若仍有内容输出,请检查操作,并重复上述操作。
卸载已有nvidia driver
可能本机上已安装过nvidia driver,但是安装更高版本的cuda需要安装更高版本的nvidia driver,查看系统是否已安装的nvidia driver
1 | sudo dpkg --list | grep nvidia-* # dpkg安装的 |
如果包含nvidia-*开头的一系列文件则说明系统已安装过nvidia driver,执行以下命令下载已有驱动
1 | sudo dpkg purge nvidia-* # dpkg或.run安装的 |
正式安装nvidia driver
ctrl+alt+f1进入文字界面(ctrl+alt+f7回到图形桌面),执行以下命令关闭图形界面
1 | sudo service lightdm stop |
进入到nvidia driver runfile所在目录执行
1 | chmod a+x NVIDIA-*.run |
参数解释:
–no-opengl-files:表示只安装驱动文件,不安装OpenGL文件。这个参数不可省略,否则会导致登陆界面死循环,英语一般称为”login loop”或者”stuck in login”。–no-x-check:表示安装驱动时不检查X服务,非必需。–no-nouveau-check:表示安装驱动时不检查nouveau,非必需。-Z, --disable-nouveau:禁用nouveau。此参数非必需,因为之前已经手动禁用了nouveau(建议手动禁用)。-A:查看更多高级选项。必选参数解释:因为NVIDIA的驱动默认会安装OpenGL,而Ubuntu的内核本身也有OpenGL、且与GUI显示息息相关,一旦NVIDIA的驱动覆写了OpenGL,在GUI需要动态链接OpenGL库的时候就引起问题。提示安装基本上都是accept,yes,当提示你nvidia-xconfig时,就视自己的电脑情况而定,如果电脑是双显卡(双独显、集显和独显)就选择不安装,如果只有一个显卡就选择安装。我的电脑是intel集显+nvidai独显,所以拒绝安装nvidia-xconfig。
在官网nvidia cuda downloads下载对应版本的cuda,然后根据自己硬件和系统选择合适的cuda进行安装,我这里下载的cuda10,下载选项如下
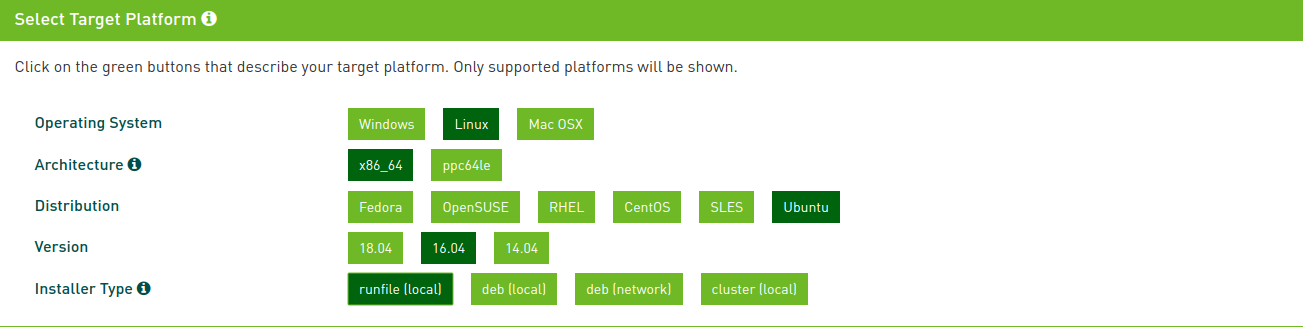
下载好之后进入到所在目录进行安装
1 | chmod a+x cuda-*.run |
安装过程中要借用/tmp目录,如果/tmp目录空间不足可以用—tmpdir指定一个tmp目录如上所示。安装过程中会询问你安装各种各样的东西,除了cuda toolkit,其它的都不需要安装,安装路径自己确定也可以保持默认,确认建立软连接到/usr/local/cuda。如果有补丁patch,则在安装完主模块之后再安装patch,方法一致。
在官网nvidia cudnn downloads下载对应cuda版本的cudnn,cudnn下载要求必须登录账户才可以,我这里下载最新的cuDNN v7.6.3 for cuda 10 .0,下载好之后解压,然后将其库文件copy到cuda中
1 | cp CUDNN_HOME/include/cudnn.h CUDA_HOME/include |
ldconfig要求.so文件是软链接,所以必须ln -sf之后再执行ldconfig上面命令中的CUDNN_HOME和CUDA_HOME分别是cudnn和cuda安装目录,安装好之后配置环境~/.bashrc
1 | # CUDA |
source ~/.bashrc之后,执行nvcc -V查看cuda版本,测试cuda是否已可用
1 | cd CUDA_HOME/samples/1_Utilities/deviceQuery |
如果最后显示pass则表明cuda安装成功,否则不可用
安装tensorflow之前查看cuda和cudnn版本号以安装相匹配版本的tensorflow
1 | 查看cuda版本 |
git clone tensorflow的官方仓库
1 | git clone https://github.com/tensorflow/tensorflow.git |
基于tag(版本)创建分支
1 | git tag # 查看分支 |
使用python3.6安装,tensorflow的源码编译安装还需要使用google的一款编译器bazel,具体安装教程以及tensoflow版本与cuda,cudnn,bazel的版本匹配请参考官网的tensorflow install.
Caution:这里记录一下我安装过程中出现的几个问题及经验,在正式bazel编译之前执行./configure进行配置,配置过程中建议使用gcc而不是clang,这样编译过程中不容易出错,然后配置过程中可能会报以下错误
1 | Traceback (most recent call last): |
这个问题可以参考github issue: find_cuda进行解决,具体做法:在third_party/gpus/find_cuda_config.py文件中找到match = pattern.match(line.decode(“ascii”)),并将其修改为match = pattern.match(line.decode(sys.stdin.encoding))即可,重新执行./configure就不会再报错了。
google提供了tensorflow多标签的docker镜像,使用docker容器安装使用tensorflow是最便捷且安全的,用户可以在tensorflow多版本之间自由切换,在服务器上使用也不用再受权限问题困扰了,而且最新的docker 19.03已经原生支持容器使用物理机上的gpu了,不再需要安装nvidia-docker来支持gpu使用了,用户只需在物理机上安装nvidia驱动,其它的都有镜像提供,喜大普奔。docker安装可以参考我之前写的一篇博客Linux下docker安装教程,至于docker下使用tensorflow镜像的教程可以参考tensorflow官方教程Docker。
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!
ubuntu桌面比较简陋,这就驱使很多人想DIY自己的一套桌面主题,如果是从零开始配置和美化ubuntu18.04,可以建议先参考Ubuntu 18.04配置及美化
工欲善其事,必先利其器
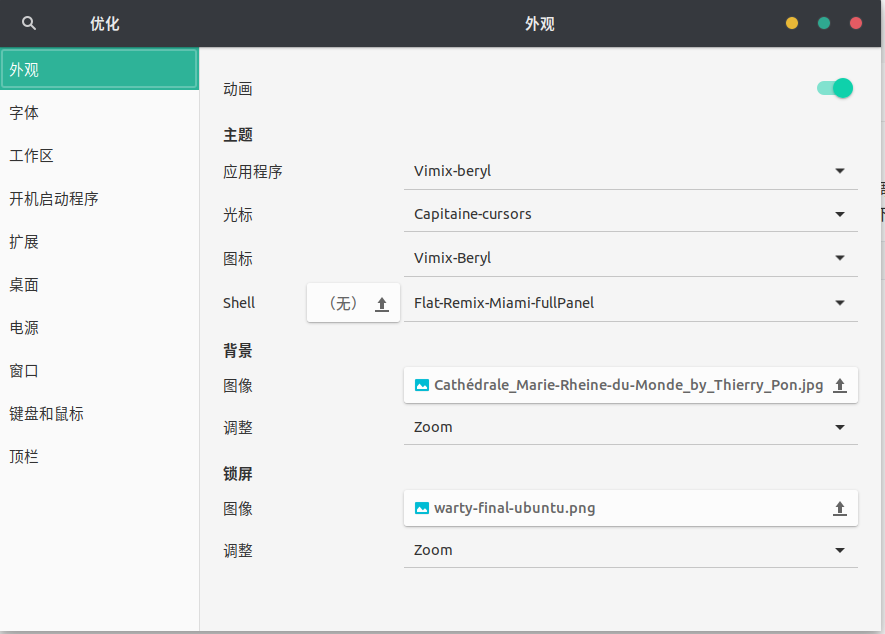
要对ubuntu进行美化就必定要用到神器gnome-tweak-tool,这是 Gnome 官方发布的一款 Gnome 调节软件, 借助这款软件, 我们可以更好地管理主题, 扩展, 字体 以及系统行为等设置项。安装方式很简单,命令行下执行
1 | sudo apt install gnome-tweak-tool |
安装tweak好之后打开界面如下
Gnome Shell Extensions 是 Gnome 的一系列插件, 类似 Chrome 的插件, 可以起到系统增强的作用。借助chrome的插件可以方便的访问gnome扩展网站并实现一键添加或删除gnome扩展程序,具体安装过程两步
sudo apt install chrome-gnome-shell接下来我们就可以在网站 GNOME Shell Extensions 安装 gnome 扩展了。
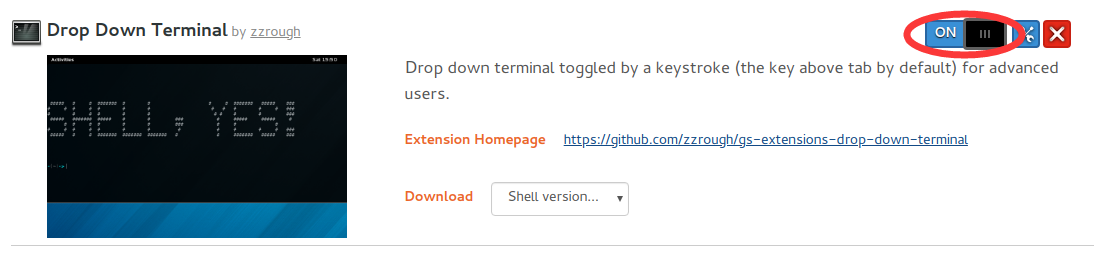
通过搜索找到自己心仪的扩展程序,点击进入详情页面,切换详情页面的“OFF”按钮即可安装对应扩展,如下图红圈标示
点击红叉即可卸载该扩展程序。有了tweak和gnome shell extension之后就可以开始DIY自己的ubuntu桌面了。
先安装一些好用的扩展程序以帮助我们提高工作效率,可参考简书:Ubuntu 18.10 美化
按下 Alt + F2,输入 r,回车重启 gnome。
有了便捷的扩展程序以后,再搭配一个让人赏心悦目的主题岂不美哉。maxOS的桌面风格很受程序猿的喜欢,所以先安利一款macOS主题桌面MCHigh Sierra,具体的制作过程可参考Ubuntu18.04主题更换为Mac OS high Sierra美化教程,按照里面的教程一步一步来即可制作出属于自己的macOS主题桌面。更多的MacOS主题安装教程可以参考给Ubuntu18.04(18.10)安装mac os主题
Caution:Sierra的原始资源地址McHigh Sierra仅提供了gnome应用主题,没有提供图标风格icon,想要获取对应主题的icon可从Ubuntu18.04-tutorials-themes获取
除了macOS主题之外还有很多其它好看的主题,可以根据个人喜好在gnome-look中进行查找。比如我个人喜欢的一套主题是Vimx-beryl Theme及其配套iconVimx-beryl Icon,这套主题的具体安装教程可参考知乎:Ubuntu 18.04 LTS 安装、美化
Caution:下载的theme可以放在系统themes目录/usr/share/themes下,也可以放在用户目录~/.themes下。而下载的icon可以放在系统icons目录/usr/share/icons下,也可以放在用户目录~/.icons下
Flat Remix个人挺喜欢的一款gnome shell风格,可以通过添加源在命令行下安装
1 | sudo add-apt-repository ppa:daniruiz/flat-remix |
然后重新打开tweak,在扩展一栏中将User themes打开之后即可切换gnome shell的风格了
zsh是mac默认的shell,而ubuntu的默认shell是bash。相比bash,zsh配合oh-my-zsh拥有更丰富的主题,使得命令行更为美观。
1 | sudo apt install zsh |
重新登录shell即可转换到zsh,接下来在用户主目录下安装oh-my-zsh
1 | sh -c "$(wget https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh -O -)" |
接着安装插件highlight,高亮语法
1 | cd ~/.oh-my-zsh/custom/plugins |
在Oh-my-zsh的配置文件中~/.zshrc中添加插件
1 | 括号中的插件名以空格分隔 |
设置zsh主题
1 | 个人觉得比较好看的zsh主题有: robbyrussell(default), agnoster, bira |
Caution:其中agnoster主题比较像之前在bash下使用的powerline,由于包含特殊的字体符号,需要安装额外的字体 Powerline-patched font才能支持主题正常显示,ubuntu下可直接使用apt安装
2
fc-cache -vf /usr/share/fonts/ #更新系统的字体缓存
zsh主题定制可以参考oh-my-zsh终端用户名设置(PS1),zsh的一些主题例如agnoster会自动添加命令行头名user@host,如果觉得这种形式使得命令行看起来很臃肿,可以在~/.zshrc中可以设置DEFAULT_USER来避免
1 | DEFAULT_USER=brooksj |
避免命令行头名臃肿还可以通过prompt_context() {}来设置
1 | 隐藏用户名和主机名 |
个人倾向于只保留用户名,最后使配置生效
1 | source ~/.zshrc |
backgound的图片可从壁纸网站wallhaven)下载,然后放到/usr/share/background中,右击桌面切换背景即可
个人所使用的应用程序、光标、图标、shell在tweak中配置如下图所示
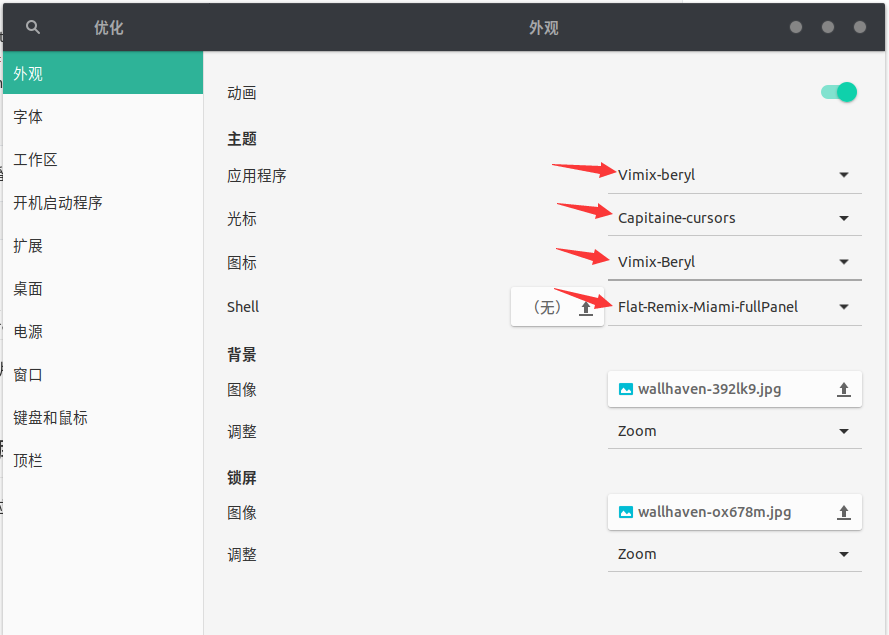
个人用到的扩展(gnome shell extensions)为
作者: brooksjay
联系邮箱: jaypark@smail.nju.edu.cn
本文地址:
本文基于 知识共享署名-相同方式共享 4.0 国际许可协议发布
转载请注明出处, 谢谢!